

Naše přeinformatizovaná doba se vyznačuje stále větším objemem dat, která jsou všem k dispozici, jakož i IT nástrojů které data statisticky zpracují a srozumitelně znázorní. Kde kdo pak propadne mylnému dojmu, že výsledná Tvrdá-Fakta-z-Dat a Čísla-Která-Nelžou říkají něco podstatného o fungování světa a rozhodne se s náboženskou vervou prosazovat „statistickou politiku“ – represi nebo zákony, jejichž jediným cílem je ovlivnit nežádoucí čísla v grafech či tabulkách. Protože statistika je přeci věda; a od doby Osvícenství věda nahradila náboženství jako vlastníka absolutní Pravdy. To vše je však nesmírně zhoubný omyl.
Samotný fakt, že někdo používá matematické vzorečky, lineární regresi v Excelu, jazyk R nebo statistické modely ještě totiž v žádném případě neznamená, že rozumí statistice nebo „pracuje s tvrdými fakty“. Statistika je totiž v jádru mechanický matematický obor: dokáže najít nějaké korelace, jenže už neříká vůbec nic o tom co z nich plyne. Pravá věda je v tom, jak očistit, zpracovat, vyhodnocovat a chápat data, která statistika dostává na vstupu a podává na výstupu – a to dělá většina lidí i institucí k uzoufání špatně a proto dochází k zavádějícím nebo dokonce úplně překrouceným a nepravdivým závěrům.
Statistický hřích prvý: extrapolace donekonečna
V roce 1894 se novináři – údajně v londýnských Timesech, ale jiné zdroje hovoří o New Yorku – dopustili následující predikce:
Během 50 let budou ulice Londýna pohřbeny pod 9 stopamu koňského trusu.
Čísla, ta „tvrdá data“, byla neúprosná: každý kůň denně defekuje mezi 7 a 17 kg trusu. V Londýně fungovalo přes 11,000 drožek a k tomu několik tisíc „autobusů“ potřebujících 12 přepřažených koní denně – dohromady 50,000 koní a 375 až 875 tun koňského trusu -, a k tomu se ještě přidávala koňská spřežení která do Londýna vozila zásoby. New York na tom byl ještě hůře – jeho 100,000 koní podle dobových pramenů vytvořilo přes 1200 tun trusu denně.
Ke všemu zde fungovala pozitivní zpětná vazba: čím více koní v daném městě jezdilo a přijíždělo do něj, tím více žrádla bylo potřeba pro ně dovézt – jak? Dalšími koňskými spřeženími, která však po vykládce v Londýně potřebovala též nažrat, takže přivézt více žrádla atd. Data tedy hovořila naprosto jednoznačně: dá se očekávat nekonečný lineární nárůst množství koňského trusu. Ten navíc láká mračna much přenášejících infekční nemoci – zkáza je neodvratná!
Zpětně víme, proč se tyto vysoce „vědecké“ predikce mýlily. Přišly nové technologie – vlaky, parní automobily a posléze auta s motory s vnitřním spalováním – a koně v krátké době nahradily ve všem kromě koníčků. Podobných predikcí jsou ovšem mračna a vůbec se za ně nestydí ani renomované časopisy, ani akademici. Například časopise Life v roce 1970 napsal:
Do roku 1985 zmenší znečištění vzduchu množství dopadajícího slunečního světla na polovinu.
Ovšem to je jen slabota v porovnání s mnoha predikcemi slovutného profesora Simona Ehrlicha, který s neochvějnou jistotou predikoval, že na znečištění vzduchu zemře ročně 200,000 Američanů nebo že v dekádě 1970-80 zemře hlady 200 milionů lidí ročně. U příležitosti prvního Dne Země v roce 1970 a vzniku environmentálního hnutí se ostatně s podobnými perlami vysloveně protrhl pytel – ono ostatně celé zelené náboženství a jeho přímý historický předchůdce, Malthusiánství, nestojí na ničem jiném, než neuvěřitelně špatné práci s daty a absurdní extrapolaci. Dejme slovo environmentalistovi Kennethu Wattovi:
Pokud bude pokračovat současný trend, globální průměrná teplota v roce 1990 bude nižší zhruba o 4°, ale v roce 2000 již o 11°. To je více než dvojnásobek toho, co by způsobilo dobu ledovou.
Jistě, „pokud bude pokračovat současný trend“. Jenže žádný strom neroste do nebes a žádný trend neroste donekonečna. Každý růst či pokles má svou mez, kde se začne zpomalovat a pak srovnávat, a téměř vždy se nakonec obrátí. Ve velkém množství případů ale není možné predikovat kdy jednoduše proto, že to závisí na známých neznámých (víme že přijde něco co trend změní, ale nevíme co ani kdy).
{kind=link}
Statistický hřích druhý: extrapolace z malého vzorku dat
Matematicko-programátorský komix XKCD vydal před lety velmi trefný vtip: statistik v něm nevěstě ukazuje graf vzniklý proložením nuly a jejího jednoho manžela a extrapoluje, že s takovou bude mít ke konci měsíce „přes čtyři tucty manželů a měla by si zřídit množstevní slevu na svatební dorty“.

Kde se vloudila chybička? Pokud vezmete za časovou osu den, pak včera měla nevěsta manželů nula, dnes má jednoho – a pak si můžete vybrat naprosto libovolně lineární nebo exponenciální růst, protože dostatečně malá datová sada to umožňuje a výsledný graf trendu pořád vykáže r (to není „číslo reprodukce“ nákazy, nýbrž korelační koeficient) blízké 1.
S dostatečně malou datovou sadou se ovšem dá kouzlit i jinak. Vzhledem k malému množství dat si můžeme zvolit kratší časový rozestup mezi pár body, čímž opět uměle zvýšíme strmost křivky. Na příkladu naší nevěsty – co takhle „před pěti minutami jsi měla 0 manželů a teď máš 1“? Data perfektně sedí, boom, raketový nárůst jako hrom.
Datová sada přitom vůbec nemusí začínat z nuly, to je jen extrém pro ilustraci. Bohatě stačí libovolné dostatečně nízké číslo, které během krátkého sledovaného období vzroste dostatečně rychle na to, aby křivka která proloží body datové sady byla dostatečně strmá. Třeba z 10 na 100 nakažených libovolnou nemocí během pár dní.
Nebo dostatečně malá a vhodně vybraná sada dat – jako když se zjistilo, že britští alarmističtí vědci své katastrofické prognózy neodvozují z plošných dat o testování zahrnujících desetitisíce lidí, nýbrž z malých studií zahrnujících maximálně stovky lidí. Pokud totiž datová sada obsahuje málo bodů, můžeme jimi šikovně proložit křivku tak, že bude stoupat naprosto extrémně a okrajové body (která taková lehce zfalšovaná křivka proložit nemůže) bude sice z daleka míjet, jenže korelační koeficient se pořád udrží nad 0,7 protože ignorovaných nehodících se bodů bude málo.
Totéž platí i pro obrovská procenta vypovídající o velkém růstu. Jiný komiks z XKCD to glosuje na příkladu „nejrychleji rostoucího“ náboženství – žádný růst zavedené organizace se stovkami členů totiž nemůže konkurovat růstu něčeho, co se z jednoho člověka rozrostlo na dva, tj. o 100 % nebo ještě lépe, na 200 % původní hodnoty (jediné slovíčko a kolik dělá). A tak podobně.

Statistický hřích třetí: v agregovaných datech vše přiřknout jedné příčině
Mnoho statistických veličin je prezentováno agregovanými daty a z nich vzniklými grafy změn v čase – typicky např. vývoj celkové výšky státního dluhu v čase, vývoj celkového počtu úmrtí v čase, vývoj celkové populace v čase apod. Výsledkem je jedna čára, která v sobě sdružuje všechny faktory které přispěly k jejímu růstu či naopak propadu. Pokud přitom víme, jaké významné události časově korelují s nějakou špičkou takového agregovaného grafu, je velmi svůdné celou špičku přičíst známé události.
Například vývoj obyvatel Českých zemí. Všichni ví, že mezi lety 1914-18 probíhala Velká válka – takže „propad populace viditelný v grafu je zcela zjevně způsoben válkou.“ Jenže pozor, Velkou válku bezprostředně následovala španělská chřipka! Takže „houby válka, může za to španělská chřipka!“ Aha, ale ta zabíjela v letech 1918-20, a to nám populace podle grafu naopak lehce stoupala. „Španělská chřipka České země nezasáhla a naopak způsobovala rození dětí!“ To vše zdánlivě „vyplývá ze statistiky“ pokud se dopustíte tohoto hříchu.
Vyjmenovali jsme však všechny faktory ovlivňující populaci naší země? Ani zdaleka ne. Co třeba taková migrace a vystěhovalci? Co německy mluvící obyvatelé země, kteří se po vzniku nezávislé RČS hlásili k jinému, než československému státnímu občanství? Co německojazyční obyvatelé kteří se vystěhovali? Co německojazyční občané, kteří byli odveleni do Velké války a sice ji přežili, ale již se nevrátili do Českých zemí a zůstali v zahraničí? Co 140,000 legionářů, kteří se do země vrátili až mezi lety 1919-20?
Nebo takový vývoj dluhu státního rozpočtu. Je to úplně jasné: „od roku 2000 vlády strašlivě rozhazují a žijí na dluh!“ Ne, je to jasné: „stále více peněz nás stojí důchody, protože rostou počty lidí v penzi!“ Nebo nás „stále více peněz stojí úroky ze státního dluhu“, které navíc mají onu strašlivou kladnou zpětnou vazbu, kterou straší novináři? A co taková inflace české měny, nemůže graf zkreslovat?
Jakmile se začneme pídit po jednotlivých položkách, rychle zjistíme, že „jedna hlavní příčina“ často neexistuje, nic není tak jasné jak se zdálo a vše je souhrou více faktorů. Vezměme si takové změny klima, resp. globální teploty. Co všechno tu hraje vliv?
-
- Cykly sluneční aktivity a jejich kombinace – Wolfův 11-letý, Haleův 22-letý, Gleissbergův 100-letý, Solheimův 190-letý, 554-letý Schovemův atd.
- Milankovičovy cykly náklonu zemské osy vůči slunci.
- Reflektivita (albedo) zemské atmosféry proti dopadajícím slunečním paprskům – zejména vodní pára.
- Odzelenění zemského povrchu a změna odpařování vlhkosti (tzn. zelená pole vs. holá hnědozem „topící“ GW energie a odnášející vodu do stratosféry, zelené střechy vs. asfaltové tepelné ostrovy apod.)
- Intenzita dopadajícího galaktického kosmického záření ovlivňujícího kondenzační jádra, tedy vznik oblačnosti, tedy albedo
- Re-radiace tepla absorbovaného „skleníkovými“ plyny na určitých vlnových délkách.
Žádný div, že žádný z „vědeckých“ modelů, které vychází z předpokladu že klima Země se dá zjednodušit na jeden jediný dominantní faktor a ostatní (víceméně) zanedbat, nefunguje a nedokáže vytvářet akurátní predikce vývoje klima v relevantní časové ose, resp. bez datových podvůdků.
To vše je ale ještě pořád jednoduché a srozumitelné. Násobně zajímavější je, když vyhodnocujeme účinnost nějakého politického opatření. To samé opatření může totiž nějaký faktor snížit (žádoucí efekt), ale jiný naopak zvýšit (nežádoucí efekt). Třeba graf úmrtí při dopravních nehodách:

V roce 2006 byl zaveden bodový systém a počet DN se smrtelnými následky stoupl. Bodový systém měl podle politiků a dopravních expertů snížit počet nehod tím, že řidiče donutí více dodržovat dopravní předpisy – zejména dodržování maximální povolené rychlosti. Zavedené sankce byly pro řadu řidičů z povolání likvidační, což ale mohlo ovlivnit počet DN oběma směry.
Pokud totiž neznáme jednotlivé faktory, jejichž suma je výslednicí grafu, máme naprostou volnost v interpretaci: „Češi se dostali k výkonným ojetinám německé provenience a začali jezdit šílenou rychlostí, jen bodový systém způsobil že nárůst DN se smrtí nebyl ještě vyšší!“ Nebo naopak: „Češi hypnotizovali tachometr aby nepřekročili povolenou rychlost ani o kilometr, díky tomu pořádně nevnímali okolí a bourali se smrtícími následky!“
Vrchol všeho ovšem ilustrují „úmrtí navíc“ (excess deaths) vykazovaná během nákazy nCOV. Alarmisté je chápají jako nezpochybnitelný důkaz, že COVID zabíjí násobně více, než běžná chřipka. Jenže nemají nic než agregovaná data – takže si rozeberme, co všechno se pod nimi skrývá.
-
-
- Úmrtí na COVID – tzn. kde COVID je morbidita. Takto je nám novináři a alarmisty vykazován celý graf.
- Úmrtí s nCOV – tzn. kde nCOV je komorbidita; drtivá většina těchto úmrtí je pouze přesunuta a koncentrována v čase, tzn. díky nCOV či COVID jako komorbiditě podlehne oběť svým ostatním morbiditám a komorbiditám o něco dříve, než jinak.
- Úmrtí na odepření lékařské péče – všechny zrušené plánované operace a vyšetření v popředí se zrušenými vyšetřeními na rakovinu.
- Úmrtí na špatnou diagnózu – všichni lidé, kteří měli respirační onemocnění které jim bylo paušálně mylně připsáno jako „COVID“ a byli odesláni do karantény bez potřebných léků.
- Úmrtí na odložení lékařské péče – když vyděšení nemocní sami ze strachu z COVID nepřišli na vyšetření/zákrok a zemřeli.
- Úmrtí z izolace v karanténě – je doložené, že řada seniorů nechápe karanténu a když jim v domovech pro seniory byly zakázány návštěvy, z pocitu osamění dostali deprese, ztratili vůli k životu a umírali.
- Úmrtí z karanténních opatření – když byli lidé zavřeni v bytech, nepohybovali se, nebyli na přímém slunci a čerstvém vzduchu, jejich imunita se propadla a pokud již měli podlomené zdraví, toto je dorazilo coby komorbidita. Stejně tak extrémní stres a strach, jaký po měsíce programově vyvolávala média, podlamuje zdraví.
- Úmrtí z lockdownu – živnostníci a podnikatelé, jimž vládní uzávěra ekonomiky zničila po celý život budované podnikání a popř. je ještě dorazila kontrolami a sankcemi z FÚ, mohou páchat sebevraždy nebo též zcela ztratit vůli k životu a zemřít; stejně tak je doložený statisticky významný nárůst domácího násilí a „domácích zabijaček“.
-
Toto všechno jsou faktory skrývající se pod špičkou grafu, který rostl a klesal v období nákazy nCOV-19. Zatímco úmrtí z prvních dvou faktorů jsou skutečně způsobená COVID či nCOV-19, všechna ostatní úmrtí jsou naopak způsobena represivní a hysterickou reakcí proti nCOV-19. Nikdo ale nemá a ani nemůže mít rozklad, jaký podíl který faktor měl – a každý, kdo tedy vyvozuje kategorické závěry o tom, co tuto špičku způsobilo, je tedy naprostý nevědecký šarlatán, byť se navenek ohání „statistikou“ a „tvrdými čísly“.
Statistický hřích čtvrtý: čarování s počátkem trendu
Každý graf průběhu nějaké veličiny – ať se jedná o úmrtí, zločiny, finance nebo globální teplotu – je jen více či méně hrubou aproximací, která se snaží proložit datové body jednou křivkou. Nevyhnutelně tak dochází k situacím, kdy graf neodpovídá změně a je extrémně zavádějící. A řada statistiků lidí používajících statistické metody jde štěstíčku napřed a grafy vysloveně manipuluje vhodně zvoleným počátkem trendu.
Podívejme se podrobněji na graf počtů dopravních nehod okolo změny pravidel pro hlášení DN, platné od roku 2009. Graf jakoby říká, že počet DN začal strmě klesat již v roce 2008, ještě před změnou pravidel; z toho by plynulo, že změna pravidel – která přišla až v polovině strmého klesání – tedy byla pouhá korelace, nikoli kauzalita.
Jenže podívejte se pořádně. V grafu je skoková změna mezi koncem roku 2008 a začátkem 2009. Kdybyste v Excelu naklikali lineární regresi pro datové body z roku 2008, čára by neměla tak výrazně klesající trend, nýbrž výrazně méně strmý:

Rozdíl strmosti trendu je 49°. A pokud by se graf trendu lámal až na okamžiku změny pravidel, byl by ještě vyšší. To už se na emočním, politickém či mediálním vnímání podepíše hodně. To je tedy jeden statistický hřích – zneužít skokovou změnu sledované veličiny a proložit ji tak, aby klesající trend zdánlivě začal dříve, než skutečně začal. Taková manipulace je ale často velmi průhledná – v jednom a tom samém grafu totiž každý vidí všechna data, která potřebuje pro kritické přezkoumání a napadené takové interpretace dat.
Podstatně zákeřnější metodou je tedy useknout všechna historická data, která způsobují „nežádoucí“ trend, a začít teprve takovými daty, která vyrobí trend žádaný, zcela odlišný. S tím mají obrovské zkušenosti klimaalarmisté, kteří systematicky vybírají počátek datové sady tak, aby vzniklý graf měl jednoznačně stoupající tendenci korelující se stoupající koncentrací oxidu uhličitého. Jen pár ukázek – dlouhodobá datová sada versus účelově vyseknutá podmnožina s žádoucím trendem:


Zatímco selektivně si vybírat začátek datové sady „aby trend vyšel“ je vysloveně podvod, v celé řadě případů se může jednat i o omyl. Typicky pokud je datová sada omezená např. změnou metodiky, nedostupností nedigitalizovaných původních dat, přesunem měřících stanic (statistika globální teploty země je silně ovlivněna tím, že po roce 2000 byly zrušeny desítky měřících stanic zejména v chladnějších regionech), nebo zcela novou technikou měřením např. s vyšší citlivostí (např. emisní normy pro pevné částice byly stanoveny na minimální úrovni detekovatelné tehdejší měřící technikou, která byla též vykázána do statistik; od té doby citlivost stoupá a s ní stoupají i statistky.)
Za domácí úkol si zkuste vyrobit graf počtu dopravních nehod v ČR kontinuálně od roku 1989 do roku 2016, který však nebude ovlivněn změnami metodiky a kde si tedy budou 100% odpovídat vykazované počty DN v letech, která se z různých zdrojů překrývají. Přeji pěknou zábavu.
Statistický hřích pátý: nesprávná agregace dat
Statistický hřích #3 mluvil o agregovaných číslech různých příčin, která se schovají pod jedním následkem vinou nesprávné interpretace, někdy udělají chybu již statistici. To pokud různá data vykazují jako jednu jedinou agregovanou veličinu. Výsledkem je veličina, jejíž velikost se náhodně mění podle toho, co je do ní započteno a co ne.
Notoricky známý příklad jsou například statistiky kriminality v USA: FBI vykazovala i počty pachatelů a obětí podle rasy, resp. etnika. Statistické vykazování pachatelů a obětí hispánského původu ovšem vykazovalo zajímavou nekonsistenci: v některých statistických tabulkách byli hispánci započteni samostatně, kdežto v jiných jako „běloši“, a jindy jako „ostatní“. Je snad jasné, že takováto zmetková, nekonsistentní statistická data nemají ani cenu papíru, na kterém jsou vytištěna.
Stejným způsobem jsou plošně znehodnocována i data o úmrtí na COVID-19: jako „oběť COVID“ jsou vykazovány i oběti dopravních nehod, násilných zločinů a jakékoli jiné příčiny smrti, kde ale zesnulý člověk měl pozitivní PCR test na nCOV-19. To se týká USA (kde to údajně začali korigovat v červnu), Itálie, Belgie (tam dokonce v domovech pro seniory nebyl potřeba ani pozitivní test, stačilo že zesnulý zakašlal) i ČR, kde MVČR výslovně říká:
Počet úmrtí v souvislosti s onemocněním COVID-19 po jednotlivých dnech zahrnuje všechna úmrtí osob, které byly pozitivně testovány na COVID-19 (metodou PCR) bez ohledu na to, jaké byly příčiny jejich úmrtí
„V souvislosti bez příčiny“ – jinými slovy „s korelací bez kauzálního vztahu“. Zde statistici sami výslovně křičí, že z takovýchto dat není možné vyvozovat žádné závěry. Jenže média i politici dělají přesný opak…
Statistický hřích šestý: posouvání nevyhnutelnosti v čase
Snad každý si musel všimnout mediální kampaně, kterou „dopravní experti“ a MDČR léta protlačovali represi proti jednak „nebezpečným mladým řidičům“ a jednak proti nezkušeným („čerstvým“) držitelům řidičského oprávnění. Zdůvodnění je typicky špatnou prací se statistikou: v grafu vynášejícím počty DN (resp. bodovaných přestupků, o čemž MDČR tvrdí že je významná korelace) oproti věku či zkušenosti je jednoznačná špička u mladých (což koreluje s čerstvými držiteli ŘP, neboť před 18 lety věku se jaksi skutečné auto řídit nesmí).
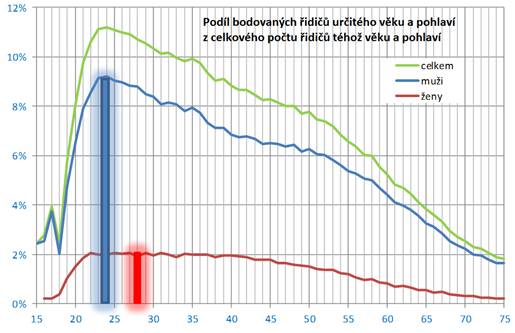
Zdánlivě se tedy jeví být jasné, že je-li zájem tuto křivku „zploštit“, je nutné zavést represi proti mladým řidičům. Jenže to je ukázkové selhání přesně kopírující hřích #3, protože ani nízký věk, ani počet let po který kdo držel ŘP v žádném případě nezpůsobuje nehodovost, pouze s nimi koreluje. Nehodovost je zde ovlivněna reálnou zkušeností s řízením.
Nezkušený řidič nemá zautomatizované všechny dovednosti nutné k řízení auta a zvládání provozu – tj. nedokáže řešit podvědomě velkou část řízení a vědomě se soustředit na nestandardní nebo obtížné -, takže je v provozu mentálně přetížen, jednoduše „nestíhá“. To zároveň vyvolává stres, který dále zhoršuje jeho kognitivní schopnosti i fyzickou zručnost. Proto většina nezkušených řidičů jezdí opatrně, leč neplynule a vykazují zvýšené riziko nehod způsobených přehlédnutím překážky, a protože zároveň vyhroceněji reagují na jakoukoli hrozbu vč. zdánlivé, častěji krizově brzdí a reagují přehnaně, což může způsobit jiné dopravní nehody.
Po nějaké době se základní řidičské dovednosti zautomatizují, řidič přestane být stresován – a právě tehdy, cca. po 1 roce zkušeností výrazně roste jeho nebezpečnost. V letectví se tomu říká „syndrom 800 letových hodin“ a je to důsledně zkorelováno na velkém vzorku – reálně se jedná o psychologický důsledek toho, že spolu se zkušenostmi a zautomatizováním procesů mladý pilot nabude nesprávného dojmu, že „už to umí“ a fakt, že s přehledem zvládá standardní situace mu vyrobí přebujelé ego, které se vymstí v okamžiku nestandardní situace. V té jeho přílišné sebevědomí zpozdí jeho reakci (již není opatrný jako nováček) a zároveň ještě nezvládne správně reagovat dost rychle (jako veterán).
Jak ale v grafu statisticky zobrazíte zkušenost? Podle počtu ujetých kilometrů? Irelevantní – je propastný rozdíl mezi ježděním mezi dvěma vesnicemi a ježděním v Praze. Podle doby držení ŘP? Irelevantní – existují zástupy lidí (statisticky převážně žen), kteří mají ŘP třeba 10 let, ale od absolvování autoškoly již nikdy neřídili. Tak podle doby placení povinného ručení? Tak to řeší pojišťovny – a důsledkem jsou zástupy lidí, kteří sice řídí a mají zkušenosti, ale nikdy na ně nebylo psané ručení, protože to je psané na rodinného příslušníka s vysokými bonusy a nízkou cenou ručení. Zkušenosti jsou prostě jeden z faktorů, které sice reálně „tvrdě“ existují, ale nejdou kvantifikovat. Jakékoli statistické operace a statistické politiky, které se snaží pracovat s jejich aproximacemi, tedy nevyhnutelně musí selhat.
Vezměme reálný příklad: řidičák na zkoušku, jaký byl po mediální masáži zaveden u nás. Reálně znamená damoklův meč: přijít o ŘP je možné již po jediném přestupku. A protože v ČR je systém úmyslně nastavený tak, že přestupky není možné nepáchat, protože ukládají jednak vzájemně si protiřečící a jednak fyzicky nesplnitelné povinnosti (s jen mírnou nadsázkou: „řidič měl a mohl očekávat, že na silnici se náhle zhmotní létající talíř, a měl tomu přizpůsobit rychlost jízdy“), co je jediné řešení? Získat řidičský průkaz, být naprosto nevyježděný elév který zoufale potřebuje nabrat zkušenosti… Ale místo toho řidičák zamknout do šuplíku a vytáhnout jej až po 2 letech, kdy se Damoklův meč zvedne.
Co takové „řešení“, založené na tupém zacházení s křivkou grafů a ignorování jeho podstaty, udělá s grafem? Pouze jej posune o tyto dva roky doprava – namísto 23-letých budou nejvíce nehod způsobovat 25-letí.
A přesně stejně je k absolutnímu neúspěchu, kamuflovanému pouze posunutím křivky v grafu o pár let doprava, odsouzen každý podobný pokus „zplošťovat křivku“ která nezobrazuje příčiny, nýbrž jen vedlejší korelace. Protože se ale křivka nezploštila, jen posunula, média a „experti“ kteří nerozumí statistice (či ji vědomě zneužívají) získají možnost znovu volat po další represi, která vrchol křivky znova jen odsune, a tak dále.
Tentýž princip funguje v statistické politice v dopravě, zdravotnictví apod. Nefunguje pouze např. ve školství, kde je dozrávání mozku opravu v příčinné souvislosti s věkem (tam je ovšem prozměnu nutné brát v úvahu statistický rozptyl od tabulek.)
Statistický hřích sedmý, smrtelný: záměna korelace za kauzalitu
Nejhorší statistický hřích, z něhož více či méně vychází většina těch ostatních, se týká propastného rozdílu mezi příčinnou souvislostí a pouze zdánlivou souvislostí nějakých dějů či dat.
Příčinná souvislost (kauzální) znamená, že nějaký děj je přímo závislý na jiném ději. Oproti tomu zdánlivá souvislost znamená, že dva či více na sobě navzájem nezávislých nezávislých dějů mají velmi podobný průběh. Jeden obrázek vydá za tisíc slov, takže viz galerii Tylera Vigena zvanou „Pochybné korelace“. Nejkrásnější z nich koreluje výdaje USA na vesmírný program, vědu a technologii s počtem sebevražd uškrcením či zadušením:

Korelační koeficient je 0,997 % – to je takřka absolutní souběh. Přesto každému mentálně zdravému člověku dojde, že mezi těmito dvěma sledovanými veličinami není žádná příčinná souvislost – rozpočet NASA v žádném případě nezpůsobuje více sebevražd oběšením a uškrcením. Korelace? Kauzalita.
Další zrada je, že i pokud mezi sledovanými veličinami existuje příčinná souvislost, může být opačná než se jeví. Například jiný z grafů z galerie Spurious correlations ukazuje souvislost mezi celkovými příjmy z počítačových heren a počtem doktorátů z vědy o počítačích (CS):

Rostly příjmy z počítačových heren kauzálně kvůli tomu, že rostl počet absolventů počítačových věd, nebo rostl počet absolventů CS protože je zaujaly počítačové hry a/nebo v nich viděli kariérní perspektivu?
Nebo zde dokonce není žádná kauzalita kvůli/protože, nýbrž pouhá nezávislá korelace – např. že jak rostl počet vyrobených mikrokontrolerů, zvyšovala se jejich dostupnost a to na jedné straně vedlo k tomu, že kde kdo začal vyrábět počítačové hry – a na straně druhé nezávisle k tomu, že se programování rozšířilo mezi mnoho zájmových kroužků, z nichž některé pak vygenerovaly i doktorandy CS?
Někteří psychologové a biologové říkají, že kvalitativní podstata lidské inteligence je schopnost vnímat kauzalitu. Pochopení kauzálního vztahu ovšem vyžaduje odpovědi na dvě otázky: jak jeden děj ovlivňuje druhý a proč jeden děj ovlivňuje druhý. Pokud tyto odpovědi chybí, nelze říct že se jedná o kauzální vztah – lze pouze říci že vidíme korelaci, která ale velmi dobře může být falešná.
Statistika ze své podstaty nemůže zodpovědět tyto otázky – může pouze objevit korelaci a nasměrovat lidi, kteří interpretují statistická data, kam se dívat a co zkoumat. Proto je jedním ze základních zákonů statistiky, že korelace neznamená kauzalitu a v žádném případě není možné korelaci za kauzalitu vydávat.
Zde ale leží jeden ze zásadních kamenů úrazu moderní civilizace. Veškerá věda od svého vzniku usilovala odpovědět otázky „co“ a „jak“, takže ve výsledku zkoumá buď vlastnosti nějakých objektů (třeba fotonů či kvarků), nebo obecně platné zákonitosti (jako Newtonovy zákony) – nebo kauzalitu způsobující různé efekty neboli následky. To totiž znamená skutečné porozumění.
S demokratizací výpočetní techniky se ale roztrhl pytel s „uživateli statistiky“ – lidmi kteří naprosto nerozumí vědě, nerozumí matematice, nerozumí statistice, nemají ani základní ponětí o práci s daty, ale touží dělat „rozhodnutí na základě tvrdých čísel“. Takoví lidé nechají počítač vyblít nějaké grafy… A pokud grafy ukáží korelaci, chovají se k ní jako kdyby objevili kauzální vztah a začnou vydávat zásadní rozhodnutí jak tuto korelaci-považovanou-za-kauzalitu ovlivnit.
Například jim někdo ukáže korelaci koncentrace CO2 v atmosféře a globální teploty – a oni okamžitě usoudí, že koncentrace CO2 způsobuje globální změny klima a že je nutné bojovat proti CO2 brutálními zákazy, sociálním inženýrstvím a daněmi. Vůbec nechápou a nerozumí tomu, že korelace může být zdánlivá (hřích #7); absolutně je nezajímá že globální teplota je funkcí mnoha proměnných a je nutné zkoumat vliv každé z nich a jejich vzájemné interakce (hřích #3); absolutně je nezajímá, že mají jednak balík mnoha dat z krátkého období (hřích #4) a jednak balík mála dat z dlouhého období (hřích #2); absolutně je nezajímá, že i kdyby zde byla kauzalita, může být opačná (teplota může způsobovat koncentraci CO2). Ne; prý že „data říkají, že CO2 může za změnu teploty“, a to ještě ke všemu pouze lidmi vypuštěný CO2. Jenže data nic takového neříkají – data říkají pouze a jedině to, že mezi koncentrací CO2 a globální teplotou je jakási korelace. Všechno nad tuto informaci již nejsou žádná data, nýbrž jejich interpretace – a to zhusta velmi bídné a povrchní.
Korunu všemu však nasadila dostupnost knihoven programovacích jazyků pro statistickou analýzu. Roztrhl se pytel s „big data“ analýzou – tedy prakticky řečeno: algoritmy strojového učení, které hledají statistické korelace v téměř kompletních (nevzorkovaných) heterogenních datech. Jak výslovně říkají propagandisté Big Data a Strojového učení,
Ve světě Big Data se nemusíme upínat na kauzalitu. Místo toho můžeme v datech vyhledávat vyhledávat vzorce a korelace (…) které nám nemusí říct přesně proč se něco děje, ale upozorní nás na to co se děje. A v mnoha situacích to úplně stačí. Pokud miliony elektronických zdravotních záznamech odhalí, že u onkologických pacientů kteří užívají určitou kombinaci aspirinu a oranžády dochází k ústupu z nádoru, pak může být přesná příčina zlepšení zdravotního stavu méně důležitá než samotný fakt, že přežili.
K tomu jen telegraficky – korelace může být obrácená, tzn. každý komu ustupuje nádor má chuť na pomerančový džus a má bolehlavy které rozhání aspirinem. Nebo může být oranžáda s aspirinem módní trend který provozují všichni, nejen onkologičtí pacienti. Atd.
U oranžády s aspirinem se záměna korelace s kauzalitou zdá jako neškodná a prospěšná, ale co když statistika ukáže, že nádor ustoupil u pacientů jejichž blízcí pili koňskou moč či Slim Fit – budou doktoři či pacienti všechny okolo nutit k pití sajrajtů „protože počítač říká“? A co když statistika ukáže, že nádor ustoupil 97% pacientům kterým byla amputována končetina – doporučí to doktor „protože počítač to říká“? Navíc se reálně stává, že když se AI mýlí, svede lékaře ke špatné diagnóze. Takové informace jsou jen zmínkou na okraji propagace strojového učení, ale stojí za to dávat pozor.
Záměna korelace za kauzalitu propagovaná vědecky negramotnými IT specialisty znamená výslovně anti-vědecké „čelem vzad“ rozumu a zběsilý úprk zpět do středověkého tmářství, lynčování a pověr, založených na přesně takových stereotypech, které byly dnešní terminologií nazvali statistickou zdánlivou korelací. „Vypít odvar z raků zahání rakovinu.“ „Kdo má mateřské znaménko na čele, ten je vrah“. Atd.
Reálným následkem tohoto zneužívání statistiky počítačovými algoritmy je svět, kdy o tom zda dostanete práci rozhodují algoritmy hodnotící zda je váš úsměv statisticky stejný jako úsměvy stávajících zaměstnanců firmy.
Zda dostanete půjčku závisí na tom, zda se typ vašeho mobilu statisticky podobá tomu co nosí zbohatlíci nebo bankrotáři.
Zda se po zatčení dostanete ven na kauci rozhodují algoritmy hodnotící statisticky „zločinnost vaší adresy“ – jako kdyby adresa způsobovala zločiny.
A zda jste odporný zločinec, který bude potrestán, mají napříště rozhodovat algoritmy které hledají korelaci, jaké části mozku se vám „rozsvěcí“ na tomografu když slyšíte určitá slova nebo vidíte fotky určitých lidí.
Prostě tmářské stereotypy jako ze středověku – není divu, že řada vědců kteří statistice rozumí proti záměně korelace za kauzalitu bije na poplach, protože věda dokazuje že zdánlivé korelace se objeví vždy a všude, i ve zcela náhodně vygenerovaných datech.
Korelace neznamená kauzalitu a každý kdo tvrdí opak je středověký tmář, který by měl dostat doživotní zákaz se ke statistické metodě nebo datům jen přiblížit. Jenže lidé chtějí mít jistotu.
Pokud mají na výběr mezi vědcem, který po pravdě přizná že neví a vědět nemůže, a mezi šarlatánem, který ukazuje svůdné grafy, ještě svůdnější zjednodušení, ohání se „statistikou“, „vědou“, „počítačovým modelováním“ a „konsensem“ a nabízí instantní rádoby-řešení v podobě statistické politiky? Každý, kdo řekne „když ta čísla nejsou správná, tak mi ukaž lepší“, se veřejně hlásí, že chce následovat šarlatána za falešnou jistotou dezinterpretovaných statistických dat a mylných závěrů.
11.10.2020 Jan Mrcasik






 (350x známkováno, průměr: 1,13 z 5)
(350x známkováno, průměr: 1,13 z 5)